清華大學建筑節能研究中心 康旭源 燕 達 孫紅三 晉 遠 崔 宏
【摘 要】建筑能耗在中國總能耗中占有非常重要的比例,建筑節能工作對全國節能減排工作具有非常重要的意義。在建筑能耗分析的過程中,基于大數據的機器學習方法對于能耗數據的分析處理非常有效可行。當前國內外已經有很多針對數據挖掘算法在建筑能耗分析應用的研究,然而當前研究缺乏體系化的方法論研究,也缺乏成熟的應用工具。本文從數據驅動模型和算法出發,針對建筑能耗數據分析領域的實際工程應用和需求,提出一套完整的能耗數據分析框架,并通過算例分析和計算進行對比驗證。最后,本文介紹了基于網站的建筑能耗數據分析軟件平臺。
【關鍵詞】建筑能耗、數據驅動、平臺、軟件
Abstract: Building energy consumption is a key factor in energy saving and carbon emission control. With the advancement of smart meters as well as mass data storage and transfer techniques, the availability of building energy data is growing rapidly. Thus, data mining methods are becoming possible and effective in the analysis of building energy consumption. Current studies have already dug into this method in both residential and commercial building aspects. However, a systematic approach remains to be established to apply data mining methods in building energy sector, and a utility software is essentially required for engineering. This research attempts to set up a framework of data mining analysis in building energy sector by: (1) applying machine learning algorithms in load predictions, clustering and categorizing, (2) defining standard input and output data format, and (3) introducing generalized validation metrics. The article concludes with a web-based utility software - Building Energy Data Analyzer.
Key words: Building energy consumption; Data-driven; Software platform
1 研究背景
隨著社會不斷的進步發展和城鎮化水平的不斷提高,中國的建筑面積呈現高速增長的姿態。建筑規模的持續增長,驅動了能源消耗的增長,截至2015年,我國建筑總面積達到了573億m2,2015年建筑運行總商品能耗高達8.64億tce,約占全國能源消費總量的20%[1],建筑能源問題已經成為社會可持續發展進程中的核心問題之一。科學分析和準確預測建筑能耗特征,是指導建筑節能方案分析和政策制定的基礎。
目前針對建筑能耗的分析主要有兩種方法:物理建模和數據驅動。物理建模方法又稱白箱模型(White-box Models),主要基于熱力學對建筑和設備系統進行詳細的建筑熱過程建模和模擬計算,得到能耗并進行相應的分析。這種方法在過去幾十年的時間里進行了充分的研究和論證,并且擁有成熟的商業軟件,如Energy Plus、DeST、eQuest等。但是這種方法需要詳細且精確的建筑熱物理參數、建筑環境參數、人員及設備作息、系統及設備信息以及氣象數據,這些數據在一些情況下難易完整精確地獲得。同時,基于物理模型的建模模擬需要模擬者充分的專業知識、嫻熟的模擬分析技能,以及豐富的工程應用經驗。這些對于一般的建筑設計、運營和管理人員來講很難完成。
第二種方法,即數據驅動的方法,則是基于已有的大量的歷史監測數據,通過數學統計和深度學習的方法,提取數據特征進行能耗數據的分析和預測。這種方法是伴隨著機器學習算法的快速發展應運而生的,是一種新興的數據分析方法。這種方法并不需要建構復雜的物理模型,而是基于歷史監測數據和統計參數進行數據特征的解構和提取。在當前傳感器和檢測儀表的普及下,這些大量的監測統計數據很容易獲取。同時,這種數據分析的方法對專業知識的要求并不高,因此一般的技術人員就可以完成[2]。這些優勢和特點,給數據驅動方法在建筑能耗數據分析中的應用帶來了很多的可能性。目前機器學習的算法研究非常廣泛,人工神經網絡、支持向量機、決策樹等算法的研究,都為數據驅動的研究方法提供了豐富的算法支撐。
Kwok, S[3]等人應用PENN(Probabilistic Entropy-based Neutral Network)算法建立起了一套針對辦公建筑的冷量預測模型。他們將逐時室外氣象參數、有人房間面積和新風機組功率作為輸入參數,訓練PENN模型,進行冷負荷的預測,并且以香港一座大型寫字樓為案例進行驗證計算,預測誤差控制在了20%以內。Yuan, J[4]等人應用基于高斯過程的貝葉斯概率模型,對既有建筑的性能參數進行概率估計。這些估計基于對現有建筑參數數據的測試和統計,根據目標建筑的一些指標(如能耗)給出參數的估計值及概率密度分布。針對新加坡的一個算例結果顯示,應用貝葉斯概率模型進行參數估計,其參數誤差從20.8%降到了6.5%,估計精度大大提升。
還有諸多基于大數據的建筑能耗數據研究,分別針對冷量預測、聚類分析、分類識別和參數估計等[5-9]。目前基于數據驅動的數學算法的開發也已經相對成熟,應用數據驅動方法進行建筑能耗分析的研究也已經取得了一些進展。然而目前相關的研究相對離散,沒有標準化的輸入輸出,缺乏完整的體系和框架。并且當前缺乏可供非專業人員使用的成熟的標準化平臺工具。
本研究針對數據驅動方法,建構了建筑能耗數據分析平臺的基本框架和標準體系,并針對數據分析的具體需求,開發了相應的計算模塊,通過具體算例驗證算法有效性,最后提出了基于網頁的數據分析軟件平臺工具。
2 研究內容
進行建筑能耗數據分析方法體系和框架研究的技術路線,首先從需求分析開始。針對當前實際工程對建筑能耗數據分析的應用點,將需求劃分為3類:負荷預測、聚類分析、分類識別。對應三類需求,我們分別匹配對應的算法尋找解決方案。在需求-算法匹配的基礎上,針對每一類需求形成標準檢驗方法,確定標準的準確性描述指標。然后根據需求確定數據的標準輸入輸出格式。最后基于網頁實現平臺化軟件工具。研究的技術路線圖如下:

2.1 負荷預測
負荷預測是基于歷史監測數據及參數對未來一段時間的能耗進行預測,是當前工程運行中普遍存在的需求。其中冷量預測對指導冷機啟停變頻、系統綜合控制具有重要意義,而電量預測對電力輸配及峰谷平衡調配也具有十分重要的意義。
負荷預測本質上是基于對周期性特征的提取以及與其他參數和相關關系構建。因此機器學習的算法諸如人工神經網絡、支持向量機等可以很好地學習這些特征并加以應用。當前進行冷量預測的核心在于對輸入變量的選取和處理的方法,自變量特征的描述方法不同,如加入“建筑中有人房間的面積”這一自變量,對擬合結果具有非常顯著的影響[3]。而類似的自變量參數的豐富性,決定了負荷預測方案的豐富性。
檢驗負荷預測效果的指標相應地也有很多,如預測絕對平均誤差(MAE)、預測均方誤差(MSE)、預測對數均方誤差(MSLE)、可釋方差得分(EVS)、絕對中值誤差(MedAE)、擬合優度(R2)等。這些檢驗指標可以用于描述歷史數據的擬合精度。如果預測數據有對應的真實監測值,則同樣可以用來對比預測精度。
對于負荷預測模型,其輸入應當是逐時的自變量(溫度、在室人數等)和因變量(能耗)值。而需要提取的特征是自變量和因變量的關系,所以應當輸入自變量向量和因變量向量,來描述特征關系F:
Y=F(X1,X2,X3,…,Xn)
同時為了預測,還應有預測自變量向量X´。因此輸入變量的應當是歷史自變量向量(如溫度向量等),歷史因變量向量Y(如能耗向量)和預測自變量向量Xi´,特征關系F即是通過機器學習算法建立的對應關系。而輸出則包含兩部分:預測因變量向量Y´和檢驗指標。這就是標準輸入輸出的定義。

2.2 聚類分析
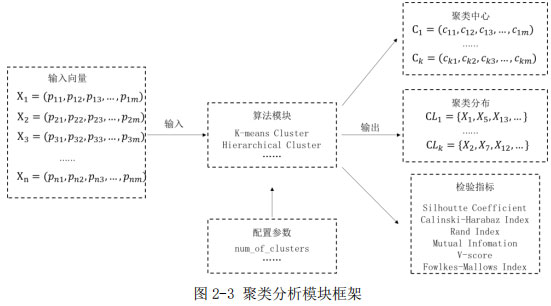
聚類分析是對一組數據點(一維或多維)按照一定的特征進行分組聚類。這種方法用于提取群體的典型特征及其分布,在人行為研究和典型建筑特性分析中有非常廣泛的應用。其具體的應用目的隨對象與需求不同而有很大差異,如用能模式聚類[6]、建筑能效聚類[10]、節能潛力聚類[11]等。但其使用的模型都是一致的,即通過一定的算法找到給定數量的聚類中心,使得類間“距離”盡量大,類內“距離”盡量小。因而其模型相對單一,所用聚類的算法也相對固定,典型的聚類算法包括K-means聚類和層次聚類等。
評價聚類效果的指標有很多,如輪廓系數(Silhouette Coefficient)、Calinski-Harabaz Index用于評價非監督學習聚類的效果,而蘭德指數(Rand Index)、互信息(Mutual Information based scores)、同質性(Homogeneity)、完整性、V指數以及Fowlkes-Mallows指數則用于評價監督學習聚類的效果。
對于聚類,其輸入即需要聚類的n維向量。而輸出可以分為兩部分,一部分是聚類結果,包含聚類中心和各樣本所屬類;另一部分是聚類評價指標,描述聚類效果的參數和因子。在這樣的標準框架下,聚類模塊的標準輸入輸入參數即如上定義。
2.3 分類識別
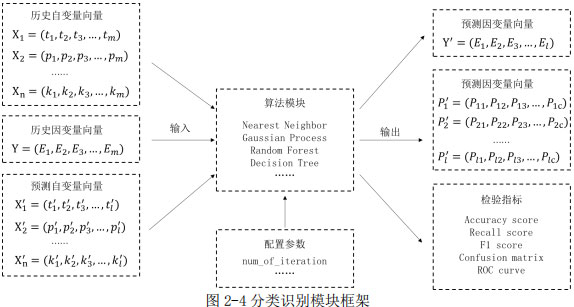
分類識別是根據給定的類別,將樣本歸屬予以劃分的一種數據分析模式,在人行為模式的歸類識別、電器模式識別等領域均有應用。分類識別在物理模型上與聚類很相似,但在數學模型上與負荷預測更為接近,分類識別可以理解為擬合預測的“離散化”,即預測的變量為離散的“類”,而非連續變量。
目前分類器算法很多,與擬合預測算法同源。基本算法包括鄰近算法(Nearest Neighbor)、支持向量機(Support Vector Machine)、高斯過程(Gaussian Process)、決策樹(Decision Tree)、隨機森林(Random Forest)等。這些算法已經在圖像識別等領域有了非常廣泛的應用。
不同于連續變量,離散變量識別預測有其獨特的檢驗指標。主要的檢驗指標包括:準確率(Accuracy score)、召回率(Recall score)、F1評分(F1 score)、混淆矩陣(Confusion Matrix)、分類報告以及ROC曲線。這些檢驗指標從不同的角度評價了分類識別的效果,具體應用時則需要根據目的選擇相應指標。
從模型結構的角度,分類識別與負荷預測具有很高的相似度,因而其標準輸入輸出格式具有高度的一致性:歷史自變量向量、歷史因變量向量、預測自變量向量作為輸入。輸出變量略為不同的是,除了給出預測因變量向量,還應給出預測概率分布向量,即描述預測為該類的概率值。同時同樣應輸出如上檢驗指標。
3 實例分析
我們以冷量預測為例,進行能耗數據分析的驗證。冷量預測所選取的案例為青島萬達廣場2015年9月3日-13日共11天的冷量監測數據,并將數據劃分為30分鐘間隔的數據點,每一個數據點包含三項參數:室外空干球溫度t、冷機作息參數(0、1表示冷機關閉與開啟)φ和冷量值(kW)。我們利用這組數據,按照前7天的冷量數據預測并驗證第八天的冷量數據,循環遞進并檢驗,完成全部數據的預測。
預測完成后,首先進行擬合檢驗。擬合誤差定義為由模型擬合訓練樣本的擬合值與真實值的相對誤差,定義式如下:

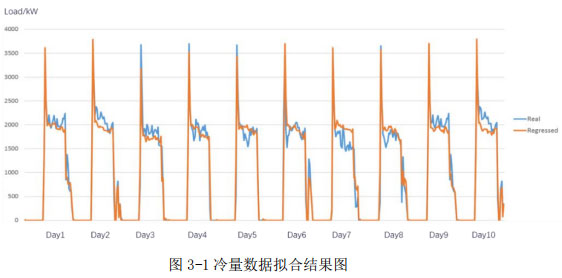
擬合的結果如下圖所示,圖下表格表示逐日擬合的平均相對誤差。從圖線及數據中可以看出,擬合誤差在10%左右。經統計,相對誤差小于30%的小時數占比93.75%

再對數據進行預測檢驗。預測誤差定義為由模型預測值與真實值的相對誤差,定義式如下:
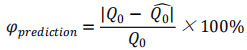
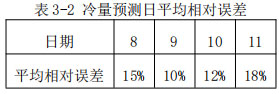
冷量預測結果如下圖所示。圖下表格表示逐日預測相對誤差。可以看出,預測的誤差也相對較小,且基本能夠準確預測趨勢和尖峰,整體預測相對誤差在15%左右。經統計,預測相對誤差小于30%的小時數占比92.71%。

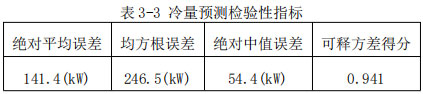
通過預測指標同樣可以判斷預測效果。下表列舉了本案例所應用的幾項檢驗指標。絕對平均誤差141.4kW,均方根誤差246.5kW,絕對中值誤差54.4kW,相對于平均能耗水平1007.5kW而言,其誤差較小,尤其是絕對中值誤差遠小于絕對平均誤差,反映了大部分能耗預測誤差都處于相對較小的水平。而可釋方差得分0.941,非常接近1,預測結果較好地反映了實際能耗的特征及變化趨勢。因此,可以認為擬合精度較高。
4 研究成果
基于以上框架,我們開發了基于網頁的建筑能耗數據分析軟件。軟件基于Python語言,應用Django庫構建網站服務器框架,應用numpy、scipy、scikit learn庫實現算法開發[12],應用matplotlib庫完成圖形繪制。軟件平臺的基本架構如下圖所示:
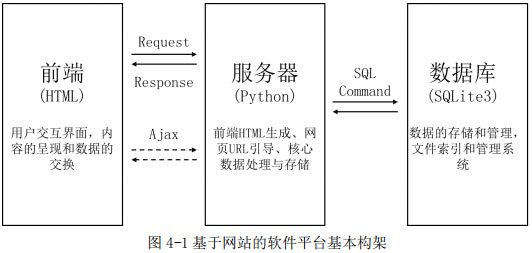
其中,服務器依照Django框架進行構建,主要分為三個模塊:配置模塊,定義時區、網址格式等;用戶模塊,定義網站用戶注冊、登錄、管理系統;計算模塊,定義網站數據分析項目創建、算法模塊調用以及結果文件輸出下載等功能。服務器后臺基本架構如下圖所示:

其中,用于數據分析的計算程序均為獨立的計算模塊,既可以通過軟件平臺進行計算,也可以作為獨立模塊被調用計算。每一個獨立模塊均具備標準格式:調用模塊的preprocessor方法可以對數據進行預處理(如標準化等);solver方法可以對數據進行分析計算;postprocessor方法對數據后處理(主要進行數據檢驗);run方法則完成預處理、計算和后處理所有步驟。
軟件平臺基于網頁端的交互設計,主要分為5個環節。第一步,功能選擇,創建項目名稱并選擇功能(負荷預測、聚類分析、分類識別等);第二步,算法選擇,選擇實現功能的算法模塊;第三步,參數設置,根據算法要求輸入相應參數;第四步,上傳數據,將原數據按照標準模版格式上傳至服務器;第五步,查看結果,在用戶管理臺界面查詢相應的項目狀態以及下載結果文件。
5 總結
本研究基于文獻綜述和工程調研,從實際的工程需求出發,建構了基于數據驅動模型的建筑能耗數據分析體系,挖掘了適應于不同需求的機器學習算法,并根據特點確定了標準檢驗指標和標準輸入輸出格式,形成了一套完備的數據分析體系。
在建筑能耗數據分析方法研究的基礎上,我們開發了建筑能耗數據分析平臺軟件,該軟件工具構建了數據分析平臺框架,實現了負荷預測、聚類分析和分類識別的數據分析功能,提供了一個實用工程工具。
本研究為數據挖掘方法在建筑能耗分析中的應用提供了體系化、標準化、模塊化的參考方案,但對具體應用的算法優化仍存在提升空間,需要進一步研究豐富算法庫的內容,提升算法庫的計算精度。
參考文獻:
[1] 清華大學建筑節能研究中心. 中國建筑節能年度發展研究報告2015[M]. 北京: 中國建筑工業出版社, 2015.
[2] Amasyali, K., & El-Gohary, N. M. (2018). A review of data-driven building energy consumption prediction studies. Renewable and Sustainable Energy Reviews, 81, 1192-1205.
[3] Kwok, S. S., & Lee, E. W. (2011). A study of the importance of occupancy to building cooling load in prediction by intelligent approach. Energy Conversion and Management, 52(7), 2555-2564.
[4] Yuan, J., Nian, V., & Su, B. (2017). A Meta Model Based Bayesian Approach for Building Energy Models Calibration. Energy Procedia, 143, 161-166.
[5] Deb, C., & Lee, S. E. (2018). Determining key variables influencing energy consumption in office buildings through cluster analysis of pre-and post-retrofit building data. Energy and Buildings, 159, 228-245.
[6] Zakovorotnyi, A., & Seerig, A. (2017). Building energy data analysis by clustering measured daily profiles. Energy Procedia, 122, 583-588.
[7] Lindelöf, D. (2017). Bayesian estimation of a building's base temperature for the calculation of heating degree-days. Energy and Buildings, 134, 154-161.
[8] Edwards, R. E., New, J., & Parker, L. E. (2012). Predicting future hourly residential electrical consumption: A machine learning case study. Energy and Buildings, 49, 591-603.
[9] Jain, R. K., Smith, K. M., Culligan, P. J., & Taylor, J. E. (2014). Forecasting energy consumption of multi-family residential buildings using support vector regression: Investigating the impact of temporal and spatial monitoring granularity on performance accuracy. Applied Energy, 123, 168-178.
[10] Vigna, Ilaria & Pernetti, Roberta & Pasut, Wilmer & Lollini, Roberto. (2018). New domain for promoting energy efficiency: Energy Flexible Building Cluster. Sustainable Cities and Society. 38. 526 - 533. 10.1016/j.scs.2018.01.038.
[11] Deb, C., & Lee, S. E. (2018). Determining key variables influencing energy consumption in office buildings through cluster analysis of pre-and post-retrofit building data. Energy and Buildings, 159, 228-245.
[12] Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., ... & Vanderplas, J. (2011). Scikit-learn: Machine learning in Python. Journal of machine learning research, 12(Oct), 2825-2830.
備注:本文收錄于第21屆暖通空調制冷學術年會(2018年10月23~27日,中國·三門峽)論文集。版權歸論文作者所有,任何形式轉載請聯系作者。